ハイパーリンク構造分析に基づく
Webページのアスペクト抽出
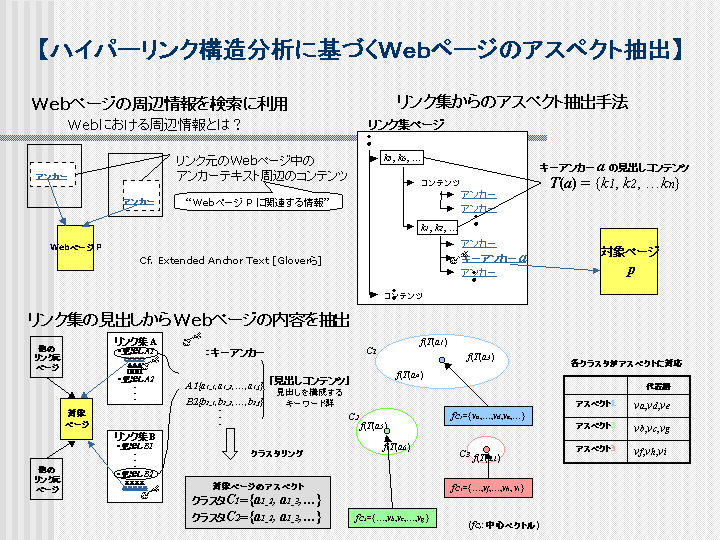
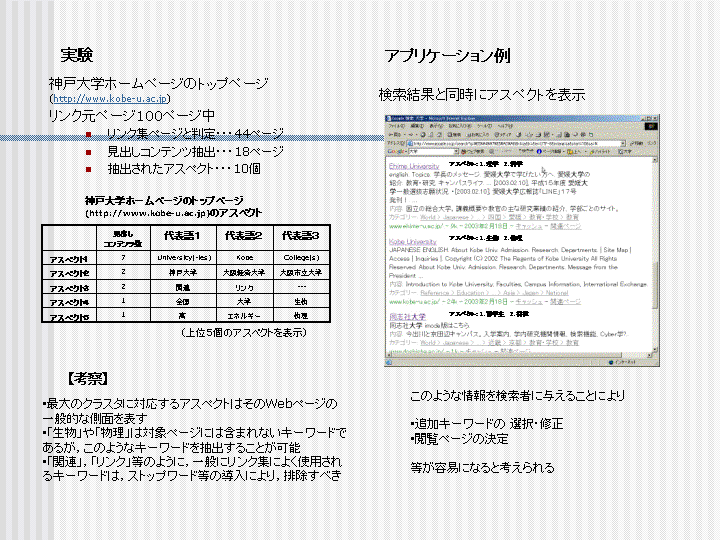
現在, Web 上には莫大な数の Web ページが散在しており,いわば,巨大なデータ ベースとなっている.この巨大なデータベースから目的の情報を取り出す手段とし て,現在では,検索エンジンを用いたキーワード検索が広く利用されている.これ は,目的の Web ページの内容に関するキーワードを入力することにより,そのキー ワードにマッチするWeb ページが検索結果として返され,この検索結果のタイトル 名や要約文を参考にしながら,目的の Web ページを発見するという手法である. この検索手法は,検索者が目的とする Web ページの内容についてある程度の予備知 識を持ち合わせており,適切な検索キーワードを選択することが可能である場合に は非常に有効な手段といえる. しかしながら,このような手法では,目的とする Web ページに関連する断片的な知 識しか持ち合わせていない状況では,所望する Web ページを検索することは非常に 困難となる.このような場合,検索者は,所持している断片的な知識をもとに試行 錯誤によって検索キーワードを決定し,さらにその検索結果から自分の所望する情 報に関連のありそうな Web ページへのリンクをたどり,内容を確認しつつ目的の Web ページを検索するという作業が必要になる.この作業は非常に煩雑であり,膨 大な数の検索結果が返された場合には,目的の Web ページにたどり着くまでに大変 な時間を要することとなる. この問題を解決するための一手段として,検索結果として返された Web ページ群が Web 上においてどのような側面を持っているのかという情報を与えることにより, 検索者が実際に探索する Web ページを絞り込みやすくするというアプローチが考え られる.しかしながら,このような情報は Web ページの周辺の情報から取り出す必 要があり,既存の検索エンジンでは取り出すことができない.ここでいう, Web ペー ジの周辺の情報とは,ある Web ページに対して直接リンクしている Web ページに 含まれるコンテンツのうち,リンク先ページに関連しているコンテンツの集合のこ とである.このようなコンテンツ集合には,ある Web ページから見たときのリンク 先の Web ページの内容が含まれており,リンク先の Web ページの側面の一つを表 していると考えられる. そこで本研究では,このような Web ページの周辺情報を表すコンテンツ集合のこと を``Web ページのアスペクト''と呼び,その抽出手法についての提案を行う.さら にプロトタイプシステムを実装して実験を行い,その結果についても考察する.